Introduction#
The BM25+ is a ranking algorithm used to rank text documents based on a relevance score.
It is used in search engines to determine which documents are the most relevant given a terms query.
The algorithm implemented is based on the
Improvements to BM25 and Language Models Examined
paper.
Implementation#
An index can be used to index the terms and the documents in which the terms occur:
1
2
| [term: apples] - doc1, doc2, doc3
[term: grapes] - doc2, doc4
|
When a user queries using the apples term then doc1, doc2 and doc3 is returned.
To score doc1, doc2 anddoc3 based on relevance the BM25+ algorithm is used.
The BM25+ is a simple mathematical formula, and it is calculated as follows:
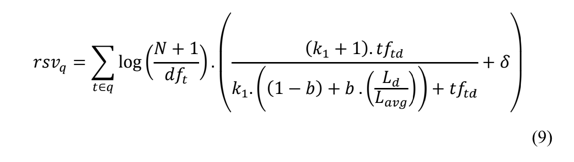
Lovins, J.B., Error evaluation for stemming algorithms as
clustering algorithms. JASIS, (1971), 22(1):28-40
We can ignore the sum for now.
If a user queries with multiple terms, the RSV (Retrieval Status Value) is the score sum of each term individually.
The k1, b and delta sign are tuning parameters. The final formula looks like:
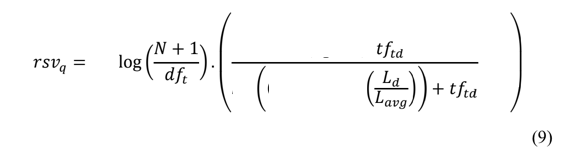
The first part is the Inverse Term Frequency, which BM25+ algorithms change by adding 1 to the N.
This frequency measures how relevant a term is to the document, N is the number of documents and
dft is the number of documents containing the term.
In the second part:
tftd is the number of times the term appears in the document.Ld - is the length of the document.Ldavg - is mean length of documents.
The output of the formula is the RSV, the higher, the more relevant the document is.
Indexing#
The indexing operation stores the document in the defined storage.
1
2
3
4
5
6
7
8
9
| /**
* The storage holds a mapping of document id -> document.
*/
private var storage: MutableMap<Int, TokenizedDocument> = HashMap()
/**
* The term frequency index holds a mapping of term -> list of documents in which the term occurs.
*/
private var termFrequencyIndex: MutableMap<String, HashSet<Int>> = HashMap()
|
And the index document is implemented as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| /**
* Indexes a document.
*/
fun index(document: Document) {
// Tokenize the document, for educational purposes and simplicity we will consider tokens only
// the words delimited by a space and transform them into lowercase.
val tokenizedDocument = TokenizedDocument(document, document.text)
// Document does not exist in index
if (!storage.containsKey(document.id)) {
storage[document.id] = tokenizedDocument
totalTokens += tokenizedDocument.getTokens().size
meanDocumentLengths = (totalTokens / storage.size).toDouble()
// Index all tokens
tokenizedDocument.getTokens().forEach {
if (termFrequencyIndex.containsKey(it)) {
termFrequencyIndex[it]?.add(document.id)
} else {
termFrequencyIndex[it] = HashSet()
termFrequencyIndex[it]?.add(document.id)
}
}
}
}
|
A terms query has the following implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| fun termsQuery(vararg terms: String): List<Pair<Double, Document>> {
val documentIds = terms.map { term ->
Pair(term, termFrequencyIndex[term.lowercase()] ?: mutableSetOf())
}.reduce { acc, pair ->
// add all documents which contain them terms to the documents set.
acc.second.addAll(pair.second)
// return
acc
}.second
// Compute the terms RSV sum for each document.
return documentIds.map {
val document = storage[it] ?: return@map null
val documentRsv: Double = terms.sumOf { term -> computeRsv(term.lowercase(), document) }
return@map documentRsv to document.document
// Sort results by highest score and filter out Infinity scores, which mean that the term does not exist.
}.filterNotNull().filter { isFinite(it.first) }.sortedByDescending { it.first }
}
|
You can browse the full source code and tests suite:
Source Code |
Unit-Tests.