Hello 👋,
I started exploring Rust a week ago due to more and more web services being written in Rust at my work place and so far I like the language, it’s simple, fast and beautiful.
My day to day programming tasks are in Python, Go and Java. I’ve also used C# for some personal projects. Picking up Rust is not that easy for me since everything I write is web services or Java programs that don’t have “low-level” logic.
In this article I will talk about my journey with Rust and my experience of using std::simd. I find things that I don’t have much experience with fascinating. I also tried using SIMD with Go but that’s above my skill level, I could not get it to work.
What is SIMD?
The SIMD stands for Single Instruction/Multiple Data. Given a vector of 128 elements.
[1,2,3, …, 128]
When you’re adding the elements, you will loop through them. A typical code will lock like this:
int sum(int * arr, int size) {
int sum = 0;
for (int i = 0; i < size; i++) {
sum = sum + *(arr + i);
}
return 0;
}
The generated assembly will look something like this:
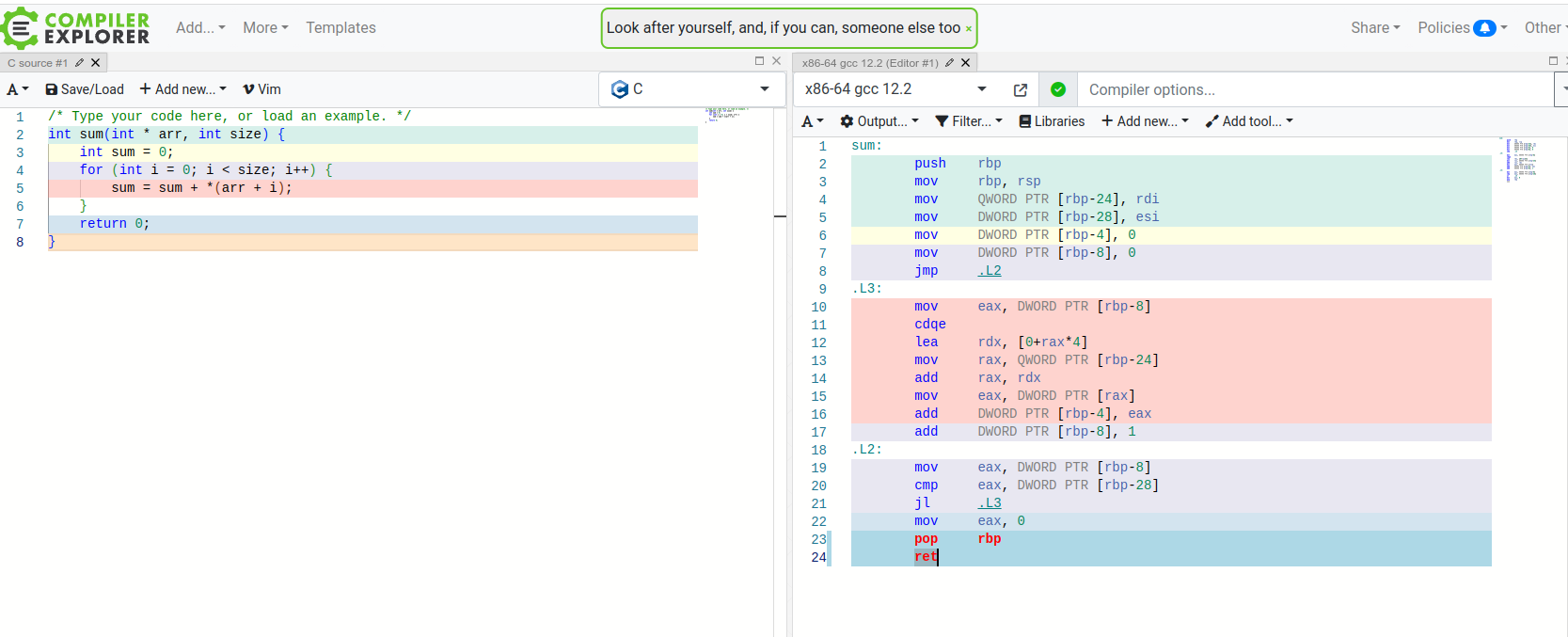 The code in RED is a the loop part, as you can see we have lots of instructions. Sometimes when the size is known, the compiler may choose to do loop unrolling, this means that instead of using JMP instructions and looping the compiler will do something like this, if the size is 3 for example:
The code in RED is a the loop part, as you can see we have lots of instructions. Sometimes when the size is known, the compiler may choose to do loop unrolling, this means that instead of using JMP instructions and looping the compiler will do something like this, if the size is 3 for example:
int sum(int * arr, int size) {
int sum = 0;
sum = sum + *(arr + 0);
sum = sum + *(arr + 1);
sum = sum + *(arr + 2);
return 0;
}
With SIMD instructions your CPU has support for assembly instructions that can work with vectors in an efficient manner. You may read more about SIMD and how it works in this excellent article Crunching Numbers with AVX and AVX2.
Basically given two vectors a and b you’re telling the compiler to do a mathematical operation on them and it will be efficient. Imagine that instead of looping though each element and executing the + operation; all elements are added at once:
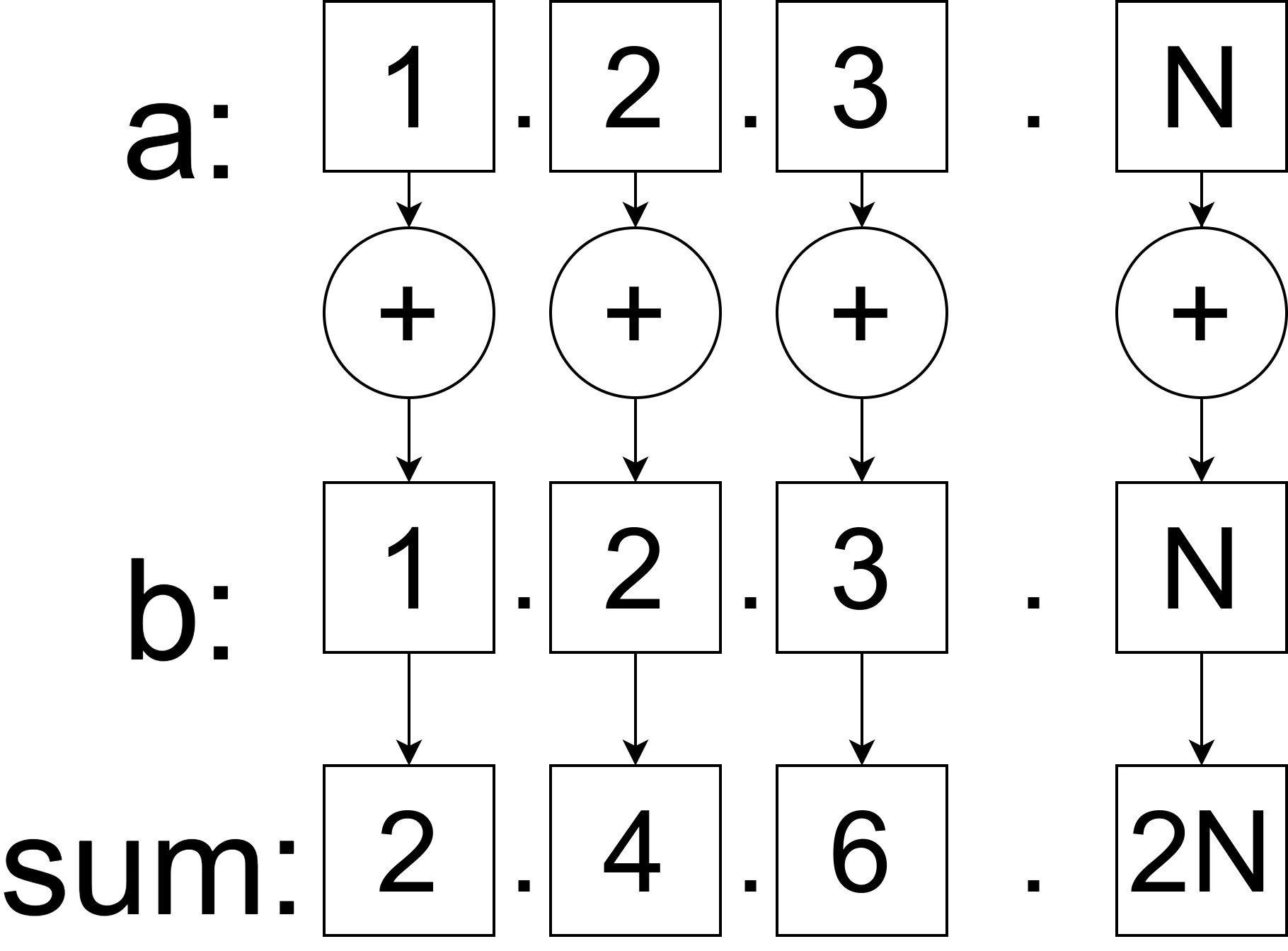 Now that we have a basic understanding of how SIMD works we can move to Rust.
Now that we have a basic understanding of how SIMD works we can move to Rust.
Rust Program to compute hamming distance
Note:
if you want to follow along or run the code from this article you will need to install rust nightly version and set it as default:
rustup install nightly
rustup default nightly
when you're done:
rustup default stable
The problem we want to solve with SIMD instructions is to compute hamming distance on two vectors equal in size. The hamming distance between [1, 2, 3] and [1, 3, 3] is equal to 1 because 2 != 3, the rest of the elements are equal.
The non-SIMD Rust function looks like this:
#[inline(never)]
fn hamming_distance_classic(a: &mut Vec<i32>, b: &mut Vec<i32>) -> u64 {
let mut distance = 0;
let length = a.len();
for i in 0..length {
if a[i] != b[i] {
distance += 1
}
}
return distance;
}
To preview the assembly a colleague recommended the cargo-show-asm crate. You can install it and run the following command to show the assembly code for the given function
cargo asm --bin rust_simd "rust_simd::hamming_distance_classic"
The generated assembly looks like a simple loop:
.LBB12_4:
cmp r8, rcx
jae .LBB12_5
mov r10d, dword ptr [rdi + 4*r9]
xor r11d, r11d
cmp r10d, dword ptr [rdx + 4*r9]
lea r10, [r9 + 1]
setne r11b
add rax, r11
mov r9, r10
cmp rsi, r10
jne .LBB12_4
pop rcx
.cfi_def_cfa_offset 8
ret
Next, I’ll show my implementation that uses simd instructions:
#[inline(never)]
fn hamming_distance_simd(a: &mut Vec
, b: &mut Vec) -> u32 {
let mut distance: u32 = 0;
let lanes = 16;
let chunks = a.len() / lanes;
for i in 0..chunks {
// create simd vectors
let a: i32x16 = Simd::from_slice(&a[i*lanes..i*lanes+lanes]);
let b: i32x16 = Simd::from_slice(&b[i*lanes..i*lanes+lanes]);
// simd XOR
let z = a.simd_ne(b);
distance += z.to_bitmask().count_ones();
}
return distance;
}
The assembly code for this function looks like this:
.LBB11_2:
cmp r8, rsi
ja .LBB11_6
cmp r8, rcx
ja .LBB11_7
movdqu xmm1, xmmword ptr [rdi + 4*r8 - 64]
movdqu xmm2, xmmword ptr [rdi + 4*r8 - 48]
movdqu xmm3, xmmword ptr [rdi + 4*r8 - 32]
movdqu xmm4, xmmword ptr [rdi + 4*r8 - 16]
movdqu xmm5, xmmword ptr [rdx + 4*r8 - 64]
pcmpeqd xmm5, xmm1
movdqu xmm1, xmmword ptr [rdx + 4*r8 - 48]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [rdx + 4*r8 - 32]
pcmpeqd xmm2, xmm3
movdqu xmm3, xmmword ptr [rdx + 4*r8 - 16]
pcmpeqd xmm3, xmm4
pxor xmm1, xmm0
pxor xmm5, xmm0
packssdw xmm5, xmm1
pxor xmm2, xmm0
pxor xmm3, xmm0
packssdw xmm2, xmm3
packsswb xmm5, xmm2
pmovmskb r10d, xmm5
mov r11d, r10d
shr r11d
and r11d, 21845
sub r10d, r11d
mov r11d, r10d
and r11d, 13107
shr r10d, 2
and r10d, 13107
add r10d, r11d
mov r11d, r10d
shr r11d, 4
add r11d, r10d
and r11d, 3855
mov r10d, r11d
shr r10d, 8
add r10d, r11d
movzx r10d, r10b
add eax, r10d
add r8, 16
dec r9
jne .LBB11_2
We can see that XMM registers are being used.
Benchmarking the code
To benchmark the code I’ve used a block of code that I’ve copied from a Rust SIMD page[1] and modified slightly.
mod bench {
extern crate test;
use self::test::Bencher;
use std::iter;
static BENCH_SIZE: usize = 128;
macro_rules! bench {
($name:ident, $func:ident) => {
#[bench]
fn $name(b: &mut Bencher) {
let mut x: Vec<_> = iter::repeat(1i32)
.take(BENCH_SIZE)
.collect();
let mut y: Vec<_> = iter::repeat(1i32)
.take(BENCH_SIZE)
.collect();
b.iter(|| {
super::$func(&mut x, &mut y);
})
}
}
}
bench!(simd, hamming_distance_simd);
bench!(vanilla, hamming_distance_classic);
}
The results are the following. The code written to use SIMD wins:
/home/denis/.cargo/bin/cargo bench --color=always --package rust_simd --bin rust_simd bench
Finished bench [optimized] target(s) in 0.00s
Running unittests src/main.rs (target/release/deps/rust_simd-2477d04109c1c861)
running 2 tests
test bench::simd ... bench: 14 ns/iter (+/- 0)
test bench::vanilla ... bench: 20 ns/iter (+/- 0)
Inlining the functions
If we remove #[inline(never)] then something interesting happens. The compiler sees that both functions are used only once and it decides to inline them.
If we run cargo asm –bin rust_simd the functions do not appear in the output:
Try one of those by name or a sequence number
0 "alloc::alloc::box_free" [15]
1 "alloc::raw_vec::RawVec
::reserve_for_push" [136]
2 "alloc::raw_vec::finish_grow" [110]
3 "core::ops::function::FnOnce::call_once{{vtable.shim}}" [19]
4 "core::ptr::drop_in_place
>" [31]
5 "core::ptr::drop_in_place
" [27]
6 "core::ptr::drop_in_place
::{{closure}}>" [7]
7 "main" [18]
8 "rand::rngs::adapter::reseeding::ReseedingCore
::reseed_and_generate" [157]
9 "rust_simd::main" [787]
10 "std::rt::lang_start" [28]
11 "std::rt::lang_start::{{closure}}" [18]
12 "std::sys_common::backtrace::__rust_begin_short_backtrace" [22]
Benchmarking the code again yields the following result:
/home/denis/.cargo/bin/cargo bench --color=always --package rust_simd --bin rust_simd bench
Finished bench [optimized] target(s) in 0.00s
Running unittests src/main.rs (target/release/deps/rust_simd-2477d04109c1c861)
running 2 tests
test bench::simd ... bench: 20 ns/iter (+/- 0)
test bench::vanilla ... bench: 0 ns/iter (+/- 0)
The vanilla block (classic hamming distance) function is much faster, and if we look at the assembly code we can see that the Rust compiler is smart and it auto vectorized the code to use SIMD instructions, unlike me the compiler is smarter and it’s code is better:
.LBB11_56:
movq xmm3, qword ptr [r15 + 4*rdx]
movq xmm4, qword ptr [r15 + 4*rdx + 8]
movq xmm5, qword ptr [rbp + 4*rdx]
pcmpeqd xmm5, xmm3
movq xmm3, qword ptr [rbp + 4*rdx + 8]
pcmpeqd xmm3, xmm4
pshufd xmm4, xmm5, 212
pandn xmm4, xmm2
paddq xmm4, xmm0
pshufd xmm3, xmm3, 212
pandn xmm3, xmm2
paddq xmm3, xmm1
movq xmm0, qword ptr [r15 + 4*rdx + 16]
movq xmm1, qword ptr [r15 + 4*rdx + 24]
movq xmm5, qword ptr [rbp + 4*rdx + 16]
pcmpeqd xmm5, xmm0
movq xmm6, qword ptr [rbp + 4*rdx + 24]
pcmpeqd xmm6, xmm1
pshufd xmm0, xmm5, 212
pandn xmm0, xmm2
paddq xmm0, xmm4
pshufd xmm1, xmm6, 212
pandn xmm1, xmm2
paddq xmm1, xmm3
add rdx, 8
add rsi, -2
jne .LBB11_56
test cl, 1
je .LBB11_59
.LBB11_58:
movq xmm2, qword ptr [r15 + 4*rdx]
movq xmm3, qword ptr [r15 + 4*rdx + 8]
movq xmm4, qword ptr [rbp + 4*rdx]
pcmpeqd xmm4, xmm2
movq xmm2, qword ptr [rbp + 4*rdx + 8]
pcmpeqd xmm2, xmm3
pshufd xmm3, xmm4, 212
movdqa xmm4, xmmword ptr [rip + .LCPI11_0]
pandn xmm3, xmm4
paddq xmm0, xmm3
pshufd xmm2, xmm2, 212
pandn xmm2, xmm4
paddq xmm1, xmm2
.LBB11_59:
paddq xmm0, xmm1
pshufd xmm1, xmm0, 238
paddq xmm1, xmm0
movq rcx, xmm1
cmp rdi, rax
je .LBB11_61
The assembly for the hamming_distance_simd function looks like this:
.LBB11_40:
cmp rdi, rax
ja .LBB11_41
cmp rdi, r12
ja .LBB11_44
movdqu xmm1, xmmword ptr [r15 + 4*rdi - 64]
movdqu xmm2, xmmword ptr [r15 + 4*rdi - 48]
movdqu xmm3, xmmword ptr [r15 + 4*rdi - 32]
movdqu xmm4, xmmword ptr [r15 + 4*rdi - 16]
movdqu xmm5, xmmword ptr [r10 + 4*rdi - 64]
pcmpeqd xmm5, xmm1
movdqu xmm1, xmmword ptr [r10 + 4*rdi - 48]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r10 + 4*rdi - 32]
pcmpeqd xmm2, xmm3
movdqu xmm3, xmmword ptr [r10 + 4*rdi - 16]
pcmpeqd xmm3, xmm4
pxor xmm3, xmm0
pxor xmm2, xmm0
packssdw xmm2, xmm3
pxor xmm1, xmm0
pxor xmm5, xmm0
packssdw xmm5, xmm1
packsswb xmm5, xmm2
pmovmskb ebp, xmm5
mov esi, ebp
shr esi
and esi, 21845
sub ebp, esi
mov esi, ebp
and esi, 13107
shr ebp, 2
and ebp, 13107
add ebp, esi
mov eax, ebp
shr eax, 4
add eax, ebp
and eax, 3855
mov esi, eax
shr esi, 8
add esi, eax
movzx eax, sil
add r9d, eax
add rdi, 16
dec rcx
mov rax, qword ptr [rsp + 8]
jne .LBB11_40
We can also force a loop unrolling if we hard-code the chunks size in hamming_distance_simd:
fn hamming_distance_simd(a: &mut Vec
, b: &mut Vec) -> u32 {
let mut distance: u32 = 0;
let lanes = 16;
// let chunks = a.len() / lanes;
for i in 0..8 {
// create simd vectors
let a: i32x16 = Simd::from_slice(&a[i*lanes..i*lanes+lanes]);
let b: i32x16 = Simd::from_slice(&b[i*lanes..i*lanes+lanes]);
// simd XOR
let z = a.simd_ne(b);
distance += z.to_bitmask().count_ones();
}
return distance;
}
Then the assembly will become:
movdqu xmm0, xmmword ptr [r15]
movdqu xmm1, xmmword ptr [r15 + 16]
movdqu xmm2, xmmword ptr [r15 + 32]
movdqu xmm3, xmmword ptr [r15 + 48]
movdqu xmm4, xmmword ptr [r14]
pcmpeqd xmm4, xmm0
movdqu xmm0, xmmword ptr [r14 + 16]
pcmpeqd xmm0, xmm1
movdqu xmm1, xmmword ptr [r14 + 32]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r14 + 48]
pcmpeqd xmm2, xmm3
pcmpeqd xmm3, xmm3
pxor xmm2, xmm3
pxor xmm1, xmm3
packssdw xmm1, xmm2
pxor xmm0, xmm3
pxor xmm4, xmm3
packssdw xmm4, xmm0
packsswb xmm4, xmm1
pmovmskb eax, xmm4
mov ecx, eax
shr ecx
and ecx, 21845
sub eax, ecx
mov ecx, eax
and ecx, 13107
shr eax, 2
and eax, 13107
add eax, ecx
mov ecx, eax
shr ecx, 4
add ecx, eax
and ecx, 3855
mov eax, ecx
shr eax, 8
add eax, ecx
movzx eax, al
movdqu xmm0, xmmword ptr [r15 + 64]
movdqu xmm1, xmmword ptr [r15 + 80]
movdqu xmm2, xmmword ptr [r15 + 96]
movdqu xmm3, xmmword ptr [r15 + 112]
movdqu xmm4, xmmword ptr [r14 + 64]
pcmpeqd xmm4, xmm0
movdqu xmm0, xmmword ptr [r14 + 80]
pcmpeqd xmm0, xmm1
movdqu xmm1, xmmword ptr [r14 + 96]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r14 + 112]
pcmpeqd xmm2, xmm3
pcmpeqd xmm3, xmm3
pxor xmm2, xmm3
pxor xmm1, xmm3
packssdw xmm1, xmm2
pxor xmm0, xmm3
pxor xmm4, xmm3
packssdw xmm4, xmm0
packsswb xmm4, xmm1
pmovmskb ecx, xmm4
mov edx, ecx
shr edx
and edx, 21845
sub ecx, edx
mov edx, ecx
and edx, 13107
shr ecx, 2
and ecx, 13107
add ecx, edx
mov edx, ecx
shr edx, 4
add edx, ecx
and edx, 3855
mov ecx, edx
shr ecx, 8
add ecx, edx
movzx ecx, cl
movzx eax, ax
add eax, ecx
movdqu xmm0, xmmword ptr [r15 + 128]
movdqu xmm1, xmmword ptr [r15 + 144]
movdqu xmm2, xmmword ptr [r15 + 160]
movdqu xmm3, xmmword ptr [r15 + 176]
movdqu xmm4, xmmword ptr [r14 + 128]
pcmpeqd xmm4, xmm0
movdqu xmm0, xmmword ptr [r14 + 144]
pcmpeqd xmm0, xmm1
movdqu xmm1, xmmword ptr [r14 + 160]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r14 + 176]
pcmpeqd xmm2, xmm3
pcmpeqd xmm3, xmm3
pxor xmm2, xmm3
pxor xmm1, xmm3
packssdw xmm1, xmm2
pxor xmm0, xmm3
pxor xmm4, xmm3
packssdw xmm4, xmm0
packsswb xmm4, xmm1
pmovmskb ecx, xmm4
mov edx, ecx
shr edx
and edx, 21845
sub ecx, edx
mov edx, ecx
and edx, 13107
shr ecx, 2
and ecx, 13107
add ecx, edx
mov edx, ecx
shr edx, 4
add edx, ecx
and edx, 3855
mov ecx, edx
shr ecx, 8
add ecx, edx
movzx ecx, cl
movzx eax, ax
add eax, ecx
movdqu xmm0, xmmword ptr [r15 + 192]
movdqu xmm1, xmmword ptr [r15 + 208]
movdqu xmm2, xmmword ptr [r15 + 224]
movdqu xmm3, xmmword ptr [r15 + 240]
movdqu xmm4, xmmword ptr [r14 + 192]
pcmpeqd xmm4, xmm0
movdqu xmm0, xmmword ptr [r14 + 208]
pcmpeqd xmm0, xmm1
movdqu xmm1, xmmword ptr [r14 + 224]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r14 + 240]
pcmpeqd xmm2, xmm3
pcmpeqd xmm3, xmm3
pxor xmm2, xmm3
pxor xmm1, xmm3
packssdw xmm1, xmm2
pxor xmm0, xmm3
pxor xmm4, xmm3
packssdw xmm4, xmm0
packsswb xmm4, xmm1
pmovmskb ecx, xmm4
mov edx, ecx
shr edx
and edx, 21845
sub ecx, edx
mov edx, ecx
and edx, 13107
shr ecx, 2
and ecx, 13107
add ecx, edx
mov edx, ecx
shr edx, 4
add edx, ecx
and edx, 3855
mov ecx, edx
shr ecx, 8
add ecx, edx
movzx ecx, cl
movzx eax, ax
add eax, ecx
movdqu xmm0, xmmword ptr [r15 + 256]
movdqu xmm1, xmmword ptr [r15 + 272]
movdqu xmm2, xmmword ptr [r15 + 288]
movdqu xmm3, xmmword ptr [r15 + 304]
movdqu xmm4, xmmword ptr [r14 + 256]
pcmpeqd xmm4, xmm0
movdqu xmm0, xmmword ptr [r14 + 272]
pcmpeqd xmm0, xmm1
movdqu xmm1, xmmword ptr [r14 + 288]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r14 + 304]
pcmpeqd xmm2, xmm3
pcmpeqd xmm3, xmm3
pxor xmm2, xmm3
pxor xmm1, xmm3
packssdw xmm1, xmm2
pxor xmm0, xmm3
pxor xmm4, xmm3
packssdw xmm4, xmm0
packsswb xmm4, xmm1
pmovmskb ecx, xmm4
mov edx, ecx
shr edx
and edx, 21845
sub ecx, edx
mov edx, ecx
and edx, 13107
shr ecx, 2
and ecx, 13107
add ecx, edx
mov edx, ecx
shr edx, 4
add edx, ecx
and edx, 3855
mov ecx, edx
shr ecx, 8
add ecx, edx
movzx ecx, cl
movzx eax, ax
add eax, ecx
movdqu xmm0, xmmword ptr [r15 + 320]
movdqu xmm1, xmmword ptr [r15 + 336]
movdqu xmm2, xmmword ptr [r15 + 352]
movdqu xmm3, xmmword ptr [r15 + 368]
movdqu xmm4, xmmword ptr [r14 + 320]
pcmpeqd xmm4, xmm0
movdqu xmm0, xmmword ptr [r14 + 336]
pcmpeqd xmm0, xmm1
movdqu xmm1, xmmword ptr [r14 + 352]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r14 + 368]
pcmpeqd xmm2, xmm3
pcmpeqd xmm3, xmm3
pxor xmm2, xmm3
pxor xmm1, xmm3
packssdw xmm1, xmm2
pxor xmm0, xmm3
pxor xmm4, xmm3
packssdw xmm4, xmm0
packsswb xmm4, xmm1
pmovmskb ecx, xmm4
mov edx, ecx
shr edx
and edx, 21845
sub ecx, edx
mov edx, ecx
and edx, 13107
shr ecx, 2
and ecx, 13107
add ecx, edx
mov edx, ecx
shr edx, 4
add edx, ecx
and edx, 3855
mov ecx, edx
shr ecx, 8
add ecx, edx
movzx ecx, cl
movzx eax, ax
add eax, ecx
movdqu xmm0, xmmword ptr [r15 + 384]
movdqu xmm1, xmmword ptr [r15 + 400]
movdqu xmm2, xmmword ptr [r15 + 416]
movdqu xmm3, xmmword ptr [r15 + 432]
movdqu xmm4, xmmword ptr [r14 + 384]
pcmpeqd xmm4, xmm0
movdqu xmm0, xmmword ptr [r14 + 400]
pcmpeqd xmm0, xmm1
movdqu xmm1, xmmword ptr [r14 + 416]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r14 + 432]
pcmpeqd xmm2, xmm3
pcmpeqd xmm3, xmm3
pxor xmm2, xmm3
pxor xmm1, xmm3
packssdw xmm1, xmm2
pxor xmm0, xmm3
pxor xmm4, xmm3
packssdw xmm4, xmm0
packsswb xmm4, xmm1
pmovmskb ecx, xmm4
mov edx, ecx
shr edx
and edx, 21845
sub ecx, edx
mov edx, ecx
and edx, 13107
shr ecx, 2
and ecx, 13107
add ecx, edx
mov edx, ecx
shr edx, 4
add edx, ecx
and edx, 3855
mov ecx, edx
shr ecx, 8
add ecx, edx
movzx ecx, cl
movzx eax, ax
add eax, ecx
movdqu xmm0, xmmword ptr [r15 + 448]
movdqu xmm1, xmmword ptr [r15 + 464]
movdqu xmm2, xmmword ptr [r15 + 480]
movdqu xmm3, xmmword ptr [r15 + 496]
movdqu xmm4, xmmword ptr [r14 + 448]
pcmpeqd xmm4, xmm0
movdqu xmm0, xmmword ptr [r14 + 464]
pcmpeqd xmm0, xmm1
movdqu xmm1, xmmword ptr [r14 + 480]
pcmpeqd xmm1, xmm2
movdqu xmm2, xmmword ptr [r14 + 496]
pcmpeqd xmm2, xmm3
pcmpeqd xmm3, xmm3
pxor xmm2, xmm3
pxor xmm1, xmm3
packssdw xmm1, xmm2
pxor xmm0, xmm3
pxor xmm4, xmm3
packssdw xmm4, xmm0
packsswb xmm4, xmm1
pmovmskb ecx, xmm4
mov edx, ecx
shr edx
and edx, 21845
sub ecx, edx
mov edx, ecx
and edx, 13107
shr ecx, 2
and ecx, 13107
add ecx, edx
mov edx, ecx
shr edx, 4
add edx, ecx
and edx, 3855
mov ecx, edx
shr ecx, 8
add ecx, edx
movzx ecx, cl
add ecx, eax
mov dword ptr [rsp + 108], ecx
lea rax, [rsp + 108]
mov qword ptr [rsp + 120], rax
mov rax, qword ptr [rip + core::fmt::num::imp::
::fmt@GOTPCREL]
You can see that by unrolling the loop there are exactly 8 code blocks that use SIMD instructions. The performance is slightly better but not by much:
/home/denis/.cargo/bin/cargo bench --color=always --package rust_simd --bin rust_simd bench
Finished bench [optimized] target(s) in 0.00s
Running unittests src/main.rs (target/release/deps/rust_simd-2477d04109c1c861)
running 2 tests
test bench::simd ... bench: 17 ns/iter (+/- 1)
test bench::vanilla ... bench: 0 ns/iter (+/- 0)
Conclusions
I’m still a beginner rustacean and my journey is just getting started. I’ve tried to outsmart the Rust compiler by using SIMD instructions manually but that didn’t work that well. Rust figured out how to optimize and vectorize the loop code that wasn’t written with SIMD instructions in mind and in the end it gave much better performance.
If you have suggestions on how to improve the code please let me know in the comments. 😀
Thanks for reading! Happy hacking!
Code
https://gist.github.com/dnutiu/8fc529d09d2872595cf2bf23d40e1cd2