Hello 👋,
In this article I will give you some tips on how to improve the throughput of a message producer.
I had to write a Golang based application which would consume messages from Apache Kafka and send them into a sink using HTTP JSON / HTTP Protocol Buffers.
To see if my idea works, I started using a naïve approach in which I polled Kafka for messages and then send each message into the sink, one at a time. This worked, but it was slow.
To better understand the system, a colleague has setup Grafana and a dashboard for monitoring, using Prometheus metrics provided by the Sink. This allowed us to test various versions of the producer and observe it’s behavior.
Let’s explore what we can do to improve the throughput.
Request batching 📪
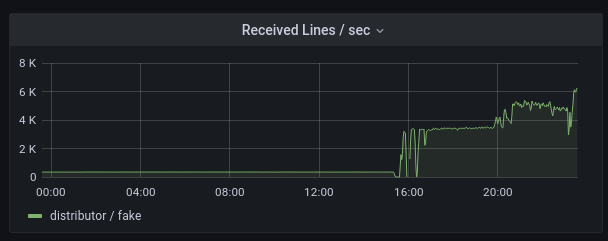 A very important improvement is request batching.
A very important improvement is request batching.
Instead of sending one message at a time in a single HTTP request, try to send more, if the sink allows it.
As you can see in the image, this simple idea improved the throughput from 100msg/sec to ~4000msg/sec.
Batching is tricky, if your batches are large the receiver might be overwhelmed, or the producer might have a tough time building them. If your batches contain a few items you might not see an improvement. Try to choose a batch number which isn’t too high and not to low either.
Fast JSON libraries ⏩
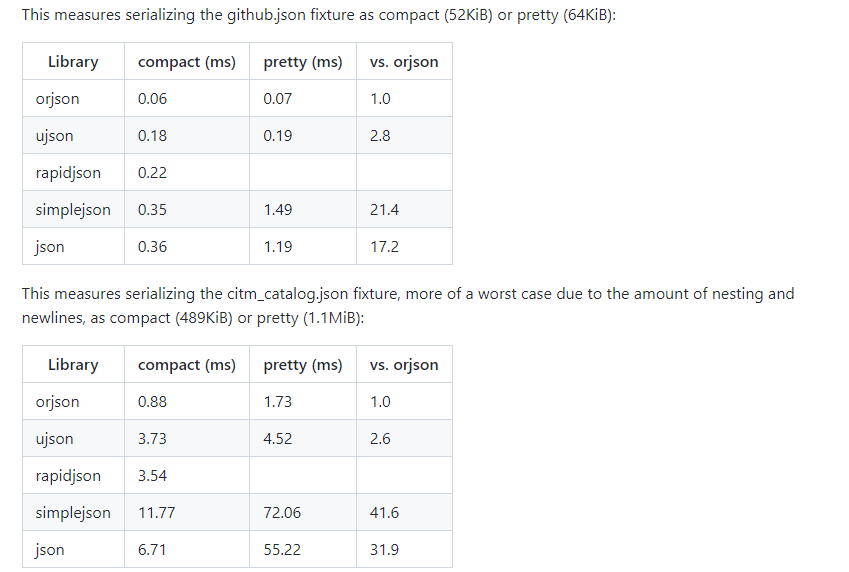
If you’re using HTTP and JSON then it’s a good idea to replace the standard JSON library.
There are lots of open-source JSON libraries that provide much higher performance compared to standard JSON libraries that are built in the language.
See:
– Python
– Golang
– C#
The improvements will be visible.
Partitioning 🖇
There are several partitioning strategies that you can implement. It depends on your tech stack.
Kafka allows you to assign one consumer to one partition, if you have 3 partitions in a topic then you can run 3 consumer instances in parallel from that topic, in the same consumer group, this is called replication, I did not use this as the Sink does not allow it, only one instance of the Producer is running at a time.
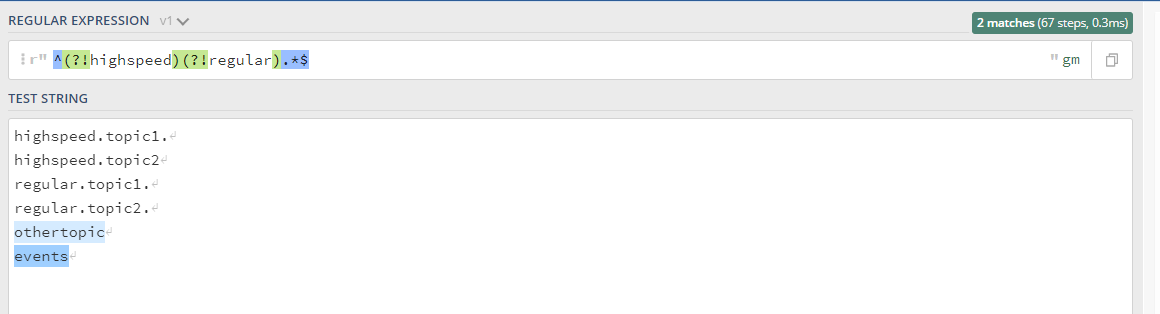
If you have multiple topics that you want to consume from, you can partition on the topic name or topic name pattern by subscribing to multiple topics at once using regex. You can have 3 consumers consuming from highspeed.* and 3 consumer consuming from other.*. If each topic has 3 partitions.
Note: The standard build of librdkafka doesn’t support negative lookahead regex expressions, if that’s what you need you will need to build the library from source. See issues/2769. It’s easy to do and the confluent-kafka-go client supports custom builds of librdkafka.
Negative lookahead expressions allow you to ignore some patterns, see this example for a better understanding: regex101.com/r/jZ9AEz/1
Protocol Buffers 🔷
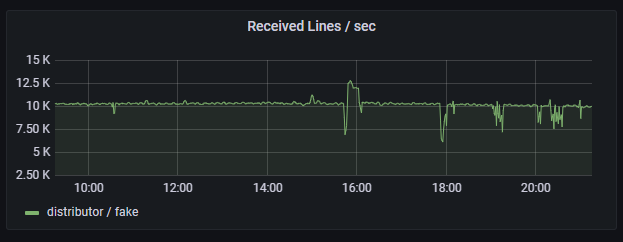 Finally, I saw a huge performance improvement when replacing the JSON body of the request with Protocol Buffers encoded and snappy compressed data.
Finally, I saw a huge performance improvement when replacing the JSON body of the request with Protocol Buffers encoded and snappy compressed data.
If your Sink supports receiving protocol buffers, then it is a good idea to try sending it instead of JSON.
Honorable Mention: GZIP Compressed JSON 📚
The Sink supported receiving GZIP compressed JSON, but in my case I didn’t see any notable performance improvements.
I’ve compared the RAM and CPU usage of the Producer, the number of bytes sent over the network and the message throughput. While there were some improvements in some areas , I decided not to implement GZIP compression.
It’s all about trade-offs and needs.
Conclusion
As you could see, there are several things you can do to your producers in order to make them more efficient.
- Request Batching
- Fast JSON Libraries
- Partitioning
- Protocol Buffers
- Compression
I hope you’ve enjoyed this article and learned something! If you have some ideas, please let me know in the comments.
Thanks for reading! 😀